مقالات زیادی درمورد مدلهای مختلف هوش مصنوعی که توانایی درک و تولید گزارشهای رادیولوژی را [حتی بهتر از خود رادیولوژیستها] دارند در سالهای اخیر مطرح شده است. اما آیا این مدلهای هوش مصنوعی «دقیقا» همانگونه که یک رادیولوژیست گزارشاش را میبیند و متوجه میشود آنرا میبینند و متوجه میشوند؟ یا روش مدلهای برای انجام این تسک یه شکل دیگری است؟
این سوالیست که مقالهی منتشر شده توسط پژوهشگران دانشگاه هاروارد (لینک) قصد پاسخگویی به آنرا دارد.

در این مقاله روشی [به نام ReXKG و بر پایهی knowledge graph] برای ارزیابی درک مدلهای هوش مصنوعی از گزارشهای رادیولوژی مطرح شده است که میتواند اطلاعات ساختاریافتهای را از گزارشهای رادیولوژی بیرون بکشد و یک گراف دانشی ایجاد کند.
این روش روابط بین ساختارهای آناتومیکی، پاتولوژیها، یافتههای تصویربرداری، دستگاههای پزشکی و... را در نظر میگیرد. در تصویر زیر نحوهی کارکرد این روش را مشاهده میکنید:
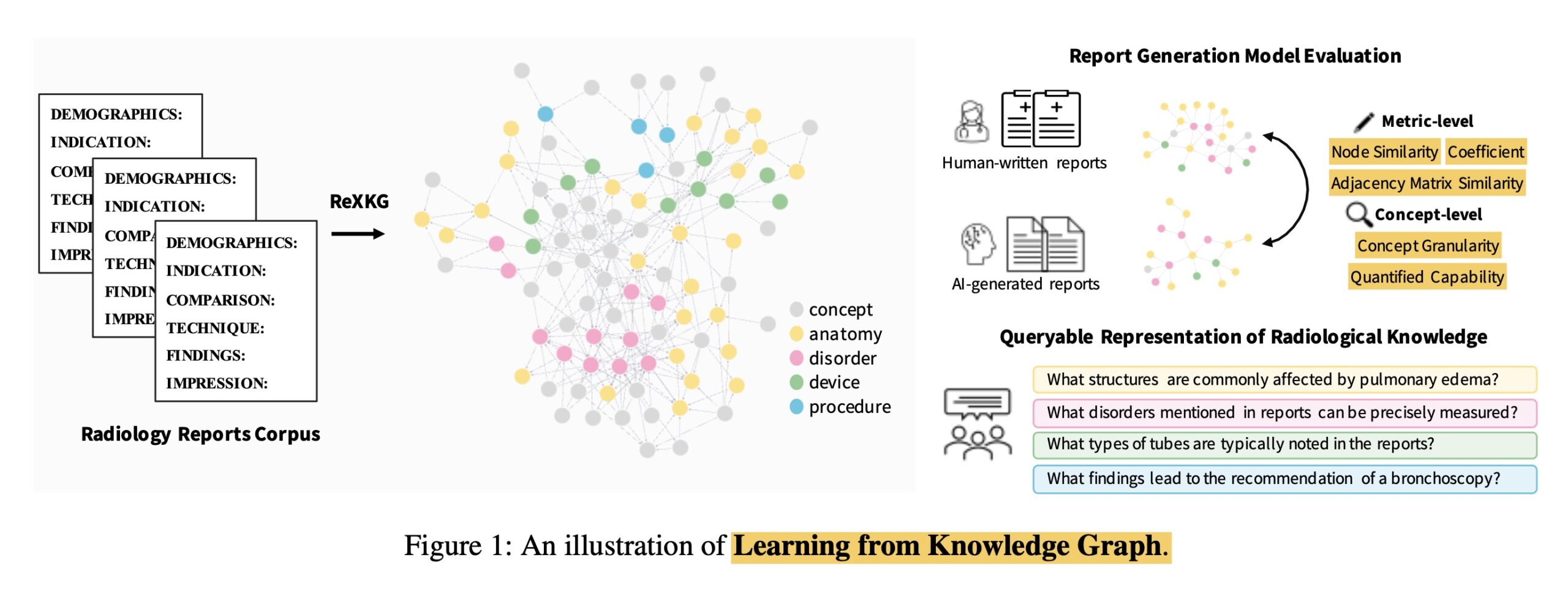
از جزئیات این روش عبور میکنیم. اما یافتههای مقاله آنقدر جذاب هستند که بیایید درموردشان بدانیم!
مهمترین یافتهی این مقاله [به عقیدهی من]، این است که مدلهای عمومی (generalist models)، پوشش وسیعتری از درک روابط بین entity های مختلف را [نسبت به مدلهای تخصصی] نشان دادهاند و این درک، نسبت به گزارشهای انسانی شکاف قابل توجهی دارد! فلذا پاسخ سوالی که پژوهشگران به دنبال آن بودهاند، فعلا «خیر» است!
این موضوع به صورت کلی یک زنگ خطر برای پژوهشگران این حیطه است که دست از پیشرفت نکشند و به [صرفا] تولیدشدن یک گزارش توسط یک مدل بسنده نکنند و تلاش بر این باشد که درک مدل از این گزارشها دقیقتر و کاملتر باشد.
این مقاله همچنین این نکتهی مهم را یادآوری میکند که گزارشهای تولیدشده توسط مدلهای هوش مصنوعی، تمایل زیادی به شبیهبودن با مفاهیم خاصی دارند که در دادههای آموزشیشان به وفور دیده شدهاند. این bias، به شدت اهمیت دارد و باز هم نیاز هرچه بیشتر به روشهای بهتری برای کاهش آنرا یادآوری میکند.
اگر به این موضوع علاقهمند هستید، پیشنهاد میکنم که اصل مقاله را هم مطالعه کنید تا در جریان جزئیات فنی آن هم قرار بگیرید.