دو روز از معرفی سری جدید مدلهای هوش مصنوعی شرکت openai میگذرد و افراد مختلفی به سراغ بررسی و تست این مدلها رفتهاند و نتایج، به معنای واقعی کلمه «شگفتانگیز» بوده است! این مدلها که برای پاسخگویی به پرسشهای پیچیده [که نیازمند استدلال و بررسی استراتژیهای مختلف و... هستند] طراحی شدهاند، زمان بیشتری را برای پردازش در لایهی استنتاج (inference) صرف میکنند و به نظر میرسد که قبل از پاسخ، «فکر میکند» و اینگونه، پاسخهای بسیار بهتری میدهد!
حالا شاید برایتان سوال پیش بیاید که این مدل چگونه به چنین دقتی رسیده است. از آنجایی که مدتیست openai دیگر جزئیات مدلهایش را منتشر نمیکند نمیتوان به صورت دقیق درمورد اینکه این مدل از چه معماریای استفاده میکند اظهار نظر کرد. اما میتوان دید که در چه روندی ساخته شده است و بر همان اساس، به نتایجی رسید.

مدتی است که تقریبا تمام شرکتهای بزرگ هوش مصنوعی در تلاش برای بهبود قابلیت استدلالکردن (reasoning) مدلهایشان هستند و با روشهای مختلفی هم این کار را انجام میدهند. یکی از روشهایی که بسیار محبوب شده است و meta هم چند ماه پیش در مقالهای (لینک)، از آن برای بهبود عملکرد مدلهایش استفاده کرد reinforcement learning (یادگیری تقویتی) است.
در این روش، مدل پس از دریافت ورودی (prompt) و قبل از ارائهی پاسخ به کاربر، همان پاسخ [و البته پاسخهای دیگری را به صورت متوالی و موازی] را مجددا بهعنوان ورودی به خودش میدهد و صحت و سقم آنرا میسنجد. در این مرحله میتواند استراتژیهای جدیدی را برای پاسخدادن امتحان کند و حتی خطاهایش را هم شناسایی و اصلاح کند. اینگونه، پاسخ بهتری به کاربر نمایش داده میشود و مدل را قادر به پاسخگویی «پرسشهایی که پیچیدگی علمی و پردازشی زیادی دارند» میکند! این، یک نوآوری نسبت به استراتژیهای قبلی [که صرفا میخواستند عملکرد generation را بهبود ببخشند] محسوب میشود و تاثیرش هم [در سوالات پیچیده] بیشتر از آنها بوده است.
همانطور که در نمودار زیر مشاهده میکنید، این مدلها میتوانند بهتر از یک متخصص یک حیطه در همان حیطه عملکرد داشته باشند. چیزی که تقریبا تمام مدلهای قبلی قادر به آن نبودند!

لازم به ذکر است که هرچند این مدلها عملکرد قابل توجهی را در زمینهی reasoning از خودشان نشان دادهاند، اما بسیاری از قابلیتهایی که در مدل قبلی (gpt-4o) وجود داشت را ندارند. از این ویژگیها میتوان به امکان جستجو در وب و آپلود فایل اشاره کرد که فایدهی بسیار زیادی برای کاربران داشت.
البته [طبق وبلاگی که خود openai برای معرفی این سری از مدلهایش منتشر کرده است (لینک)]، هدف این مدلها هم جایگزینی مدلهای قبلی در «کوتاهمدت» نیست و openai، به عقیده ی من، با معرفی آنها قصد پیروزشدن در مسابقهی بهبود inference مدلها [بین شرکتهای در حال تلاش] را داشت که به هدفاش هم رسید. احتمالا در آینده با عمومیتر شدن کاربرد این مدلها و افزایش featureهایی، بتوان آنها را جایگزین مناسبی برای مدلهای قبلی در نظر گرفت و این، نشان از توانایی و استراتژی دقیق openai دارد که محصولات خوب خودش را با محصولات به شدت بهتری جایگزین میکند!
از همهی این موضوعات که بگذریم، معرفی این مدلها، هشداری هم به پزشکان محسوب میشود! پروفسور derya unutmaz که یک پزشک و ایمونولوژیست برجسته است، با منتشرکردن توییت زیر (لینک)، این مدلها را هشداری برای کسانی که میخواهند شغل پزشکی را انتخاب کنند دانست. البته توییت ایشان [در حال حاضر] کمی اغراقآمیز به نظر میرسد و علت نقلکردنش صرفا این بود که سر و صدای زیادی داشته است و پزشکان و مهندسان زیادی به آن واکنش نشان دادهاند.

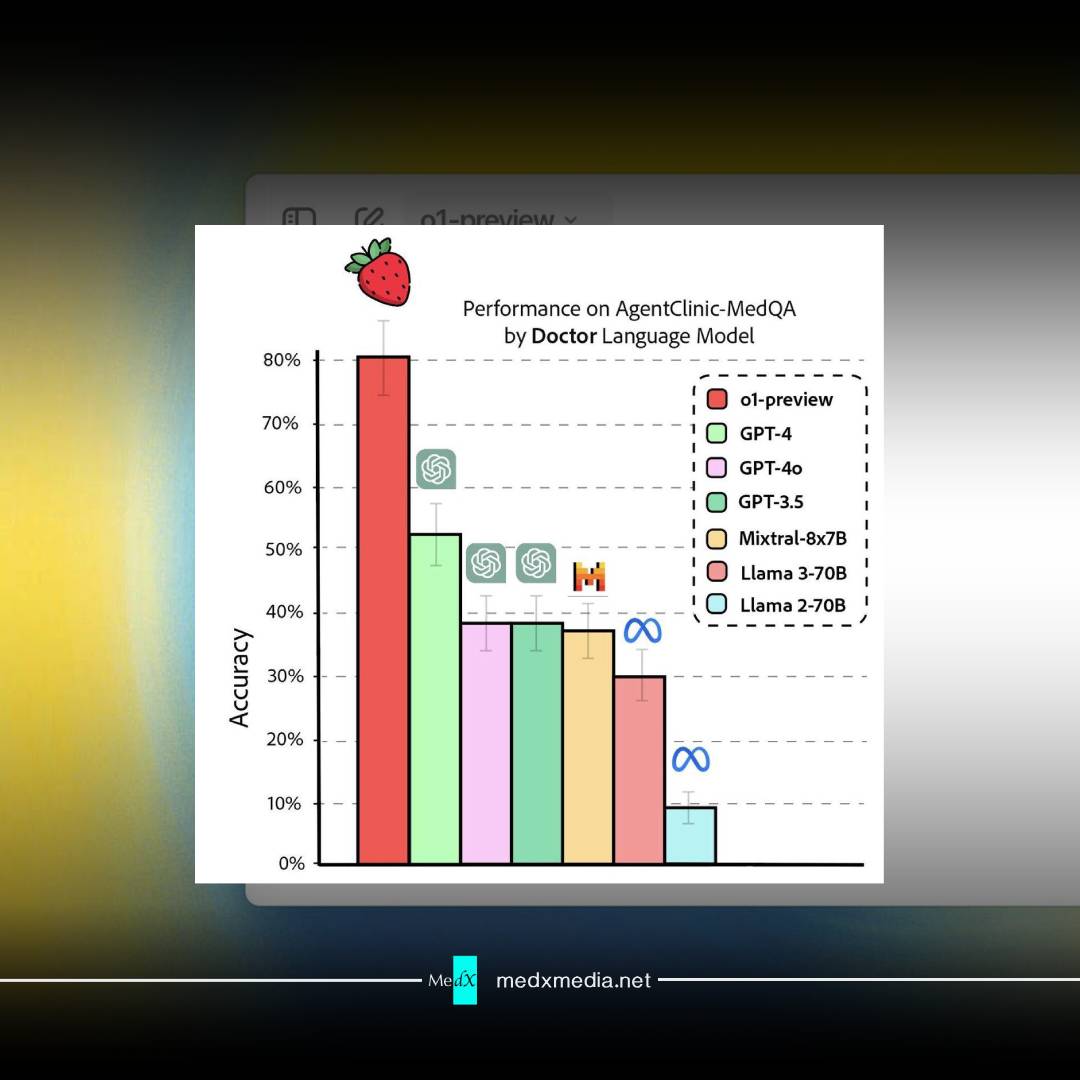
ایشان همچنین تصویر مقایسهی عملکرد مدل جدید (o1) و مدلهای قبلی بر روی سوالات پزشکی را هم منتشر کرد و در ادامه میتوانید شدت این تفاوت را ملاحظه کنید.

حواشی پیرامون این مدل بسیار زیاد بوده و ما هم صرفا به بیان برخی از آنها بسنده کردیم. برای مشاهدهی ویدئوهای مربوط به کاربرد این مدل در زمینههای مختلف [که خود openai منتشر کرده است] میتوانید به صفحهی یوتیوب آنها (لینک) مراجعه کنید.
امید است که با پیشرفت روز به روز هوش مصنوعی شاهد افزایش کاربرد آن در سلامت هم باشیم و آیندهای سالمتر را تجربه کنیم.